周末打了 Google CTF。这貌似是我第一次打 Google
CTF。由于比较摸只做了一道题。
很有意思的一个题,这道题加深了我对 ELF 文件格式的理解。
ELDAR
题目给了一个elf:
eldar,一个makefile,一个C源文件。C源文件只包含一句serial字符串的定义。makefile中告诉我们运行的方法,首先编译libserial.so,eldar需要加载libserial.so。题目告诉我们只需要修改serial的内容而无需对serial.c做其他修改。
elf
的入口点之后都无逻辑,所有的逻辑都在加载时完成。ld解析ELF重定位表,解析每个表项的过程中,通过重定位实现读取/写内存,重定位时的addend实现加法,继而实现乘法。由此实现了RC4、矩阵乘法、以及一个变种的矩阵运算,完成flag校验。由于没有跳转逻辑,整个解析的重定位表非常大。不过循环的代码有相似性,可以慢慢总结归纳出来。
具体的原理没有分析的特别细致,只是找到了调试的办法,在ld中两个特定的地方下断点,观察内存的值慢慢总结出算法。
所需要调试分析的代码是在ld中的,因此需要ld的调试符号和源代码。我解题用的系统是opensuse,可以用zypper直接安装调试符号和源代码,且不需要额外配置。
1 sudo zypper install glibc-debuginfo glibc-debugsource
ubuntu下可以通过apt安装:
1 sudo apt install libc6-dbg glibc-source
glibc-source包只包含了一个glibc-2.35.tar.xz文件,还需要手动解压:
1 2 cd /usr/src/glibc/ sudo tar xvf ./glibc-2.35.tar.xz
gdb ./eldra启动调试后,我们需要断在 ld
中。可以用starti命令从 ld 开始调试,此时的入口点是 ld
的入口点。在 opensuse 下 gdb 直接可以找到 glibc 的源代码,但 ubuntu
下不行。一个解决办法是直接把 elf
放到源码根目录下调试。sudo cp eldar /usr/src/glibc/glibc-2.35/
我在解题用的 Linux 发行版是 opensuse, 和 ubuntu 22.04 的 libc 都是
2.35 版本,源码应该是完全一样的。
如果不熟悉 glibc,
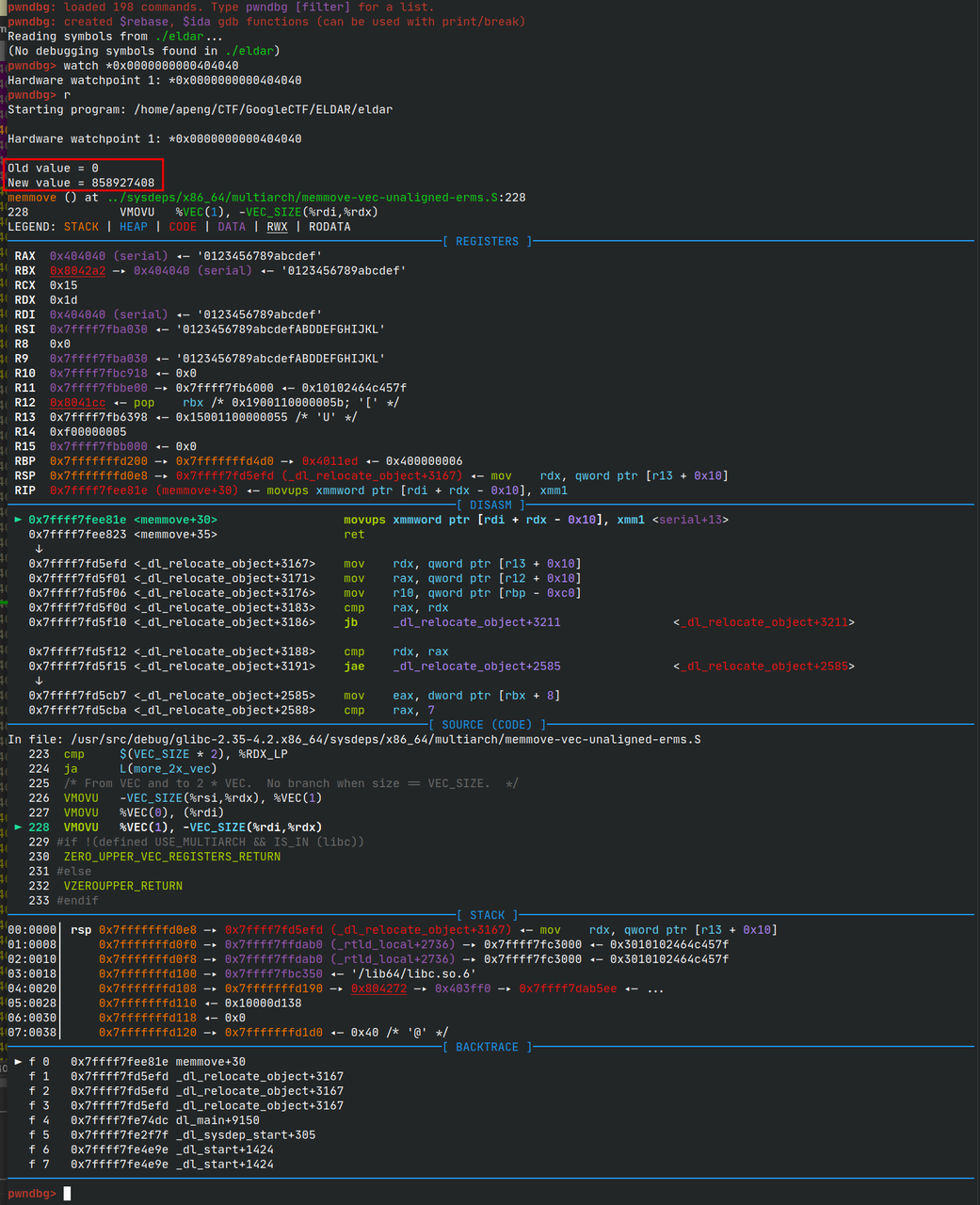
可能很难找到关键的处理ld的位置。我是通过硬件断点找到的。对 eldar 中的
serial 下硬件断点b *0x0000000000404040,会断在一个 memove
中,看起来是要复制到 serial
01
再单步跟出函数,调用 memcpy 的位置位于 dl-machine.h,这里就是处理
rela
的核心部分。注意看dl-machine.h的326行,elf_machine_rela
函数有一个 switch 结构,这里应该就是处理 rela
的各个r_type的地方了。断在这里,我们就能有对 rela
进行“单步调试”的能力了。然而实测的时候只有R_X86_64_COPY和R_X86_64_64两种会成功在这断下来,其他的可能被优化掉了,或者根本不走这里。不过这两种也够解这道题了。
1 b /usr/src/debug/glibc-2.35-4.2.x86_64/sysdeps/x86_64/dl-machine.h:326
下断点后如果重新运行,我们并不会断到 eldar 的重定位部分,因为除了
eldar,ld 还要重定位 libc 等其他库。为了找到第一个 eldar
命中这里的地方,我们可以用条件断点。0x804272
开始是重定位表,前三个表项都还算正常,我们可以用第一个对__libc_start_main的重定位来过滤:
1 2 3 4 5 starti b /usr/src/debug/glibc-2.35-4.2.x86_64/sysdeps/x86_64/dl-machine.h:326 if (reloc->r_offset == 0x403FF0) r d 1 b /usr/src/debug/glibc-2.35-4.2.x86_64/sysdeps/x86_64/dl-machine.h:326
这样,我们就相当于断在了 rela 的"入口点",并且能够"单步调试"。
翻阅文档并结合调试,我们能推断出R_X86_64_RELATIVE的作用应该是直接将r_offset赋值为r_addend的内容,按照
x86 汇编理解就是 mov qword ptr [r_offset], r_addend
IDA 中看到的重定位表内容和实际文件中的是不一样的,因为 ida
会模拟完成重定位的过程,对于R_X86_64_RELATIVE这种会模拟执行一遍,所以我们看到的8042BA处的内容是
256 个qwrod,对应 0-0xFF
,实际上是由804ACA开始的重定位代码修改的。通过调试或者观察文件原始的内容,可以发现这里的原始内容是<0x804000, 8, 0>,而804000的位置一直是
0,可以理解为什么都没做,也就是 nop 指令。
1 2 3 4 LOAD:00000000008062E2 Elf64_Rela <8040CCh, 8, 0> ; R_X86_64_RELATIVE mov qword ptr [0x8040CC], 0 以后将直接写作: [0x8040CC] = 0
由于0x8042BA的初始值为 0-0xFF ,我们将其称为 SBOX。
继续调试并在 494 行的 call
下断点,可以发现,<806352h, 200000005h, 0>的作用是
memcpy。其 dst
是当前Elf64_Rela结构体的r_offset字段,而 src 和
n
定义为第三个(下标为2)Elf64_Sym结构的st_value和st_size字段。这两个字段刚好被上方紧挨着的两个R_X86_64_RELATIVE所修改。因此以下这三条重定位等价于一个memcpy函数:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 LOAD:00000000008062FA Elf64_Rela <80409Ch, 8, 8042BAh> ; R_X86_64_RELATIVE +8042BAh LOAD:0000000000806312 Elf64_Rela <8040A4h, 8, 8> ; R_X86_64_RELATIVE +8 LOAD:000000000080632A Elf64_Rela <806352h, 200000005h, 0> ; R_X86_64_COPY ^ ┌-------------------------┘ | memcpy(0x806352, [0x80409C], [0x8040A4]) 等价于 memcpy(0x806352, 0x8042BA, 8) 0x806352 是当前这一句的r_offset 0x8042BA 和 8 是由当前这一句的r_info的高int32决定的,也就是2,对应Sym[2]的st_value和st_size 以后将写作: [0x806352] = [0x8042BA]
R_X86_64_64的作用是,重定位一个 64
位的数据,将sym[idx].value+r_addend的结果赋值给r_offset。因此等价于一个加法操作:
1 2 3 4 5 6 7 8 9 LOAD:0000000000806342 Elf64_Rela <8040CCh, 400000001h, 0> ; [0x8040CC] = [0x8040CC] + [0x8042BA] ^ ^ ^ ^ | | └---------------┐ | └-------------------------这个0x8040CC为&Sym[4].st_value 这个0x8040CC来自于Rela.r_offset ---------┘ | 这个0x8042BA是Rela.r_addend,由上文被R_X86_64_COPY修改 LOAD:000000000080635A Elf64_Rela <806352h, 8, 0> ; R_X86_64_RELATIVE 此处将 0x806352 恢复为0
R_X86_64_32的作用和R_X86_64_64类似,不过操作的是
32 位数据。在本题里只用来清空一个 int64
的第1至5字节(由于没PIE,就等价于将一个 int8 无符号拓展到
int64),例如806432这一句:
1 2 3 4 LOAD:0000000000806432 Elf64_Rela <8040CDh, 10000000Ah, 0> ; R_X86_64_32 dword ptr [0x8040CD] = dword ptr [0x804084] + 0 ; [0x804084]来自于 Sym[1].value,值为0 等价于 dword ptr [0x8040CD] = 0 dword ptr [0x8040CD] 刚好是 [0x8040CC] 的第1-5字节,且由于6-8字节为0,其实等价于将0x8040CC这个字节扩展到64bit
总结一下从 806372 开始的内容;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 LOAD:0000000000806372 Elf64_Rela <80409Ch, 8, 404040h> ; R_X86_64_RELATIVE +404040h LOAD:000000000080638A Elf64_Rela <8040A4h, 8, 1> ; R_X86_64_RELATIVE +1 LOAD:00000000008063A2 Elf64_Rela <804114h, 200000005h, 0> ; R_X86_64_COPY byte ptr [0x804114] = byte ptr [0x804040] ; byte ptr代表取int8的数据,等同于 memcpy(0x804114, 0x804040, 1) 0x804114 里开始为0x804000,假设flag[0] = 0x30,执行后为0x804030 LOAD:00000000008063BA Elf64_Rela <80409Ch, 8, 804114h> ; R_X86_64_RELATIVE +804114h LOAD:00000000008063D2 Elf64_Rela <8040A4h, 8, 8> ; R_X86_64_RELATIVE +8 LOAD:00000000008063EA Elf64_Rela <806412h, 200000005h, 0> ; R_X86_64_COPY [0x806412] = [0x806412] 将0x804030 拷贝到 0x806412,注意 0x806412 是一句的r_addend LOAD:0000000000806402 Elf64_Rela <8040CCh, 400000001h, 0> ; R_X86_64_64 [0x8040CC] = [0x8040CC] + [0x804114] ; 这里的0x804114由上一句拷贝而来 此时 0x8040CC 内为 0x804030 LOAD:000000000080641A Elf64_Rela <806412h, 8, 0> ; R_X86_64_RELATIVE [0x806412] = 0 恢复 0x806412 的值 LOAD:0000000000806432 Elf64_Rela <8040CDh, 10000000Ah, 0> ; R_X86_64_32 dword ptr [0x8040CD] = dword ptr [0x804084] + 0 ; [0x804084]来自于 Sym[1].value,值为0 等价于 dword ptr [0x8040CD] = 0 dword ptr [0x8040CD] 刚好是 [0x8040CC] 的第1-5字节,且由于6-8字节为0,其实等价于将0x8040CC这个字节扩展到64bit LOAD:000000000080644A Elf64_Rela <80409Ch, 8, 8042BAh> ; R_X86_64_RELATIVE +8042BAh LOAD:0000000000806462 Elf64_Rela <8040FCh, 200000005h, 0> ; R_X86_64_COPY [0x8040FC] = [0x8042BA] LOAD:000000000080647A Elf64_Rela <80409Ch, 8, 8040CCh> ; R_X86_64_RELATIVE +8040CCh LOAD:0000000000806492 Elf64_Rela <8064BAh, 200000005h, 0> ; R_X86_64_COPY LOAD:00000000008064AA Elf64_Rela <8040E4h, 400000001h, 0> ; R_X86_64_64 LOAD:00000000008064C2 Elf64_Rela <8064BAh, 8, 0> ; R_X86_64_RELATIVE [0x8040E4] = [0x8040CC] + [0x8040CC] LOAD:00000000008064DA Elf64_Rela <80409Ch, 8, 8040E4h> ; R_X86_64_RELATIVE +8040E4h LOAD:00000000008064F2 Elf64_Rela <80651Ah, 200000005h, 0> ; R_X86_64_COPY LOAD:000000000080650A Elf64_Rela <8040E4h, 500000001h, 0> ; R_X86_64_64 LOAD:0000000000806522 Elf64_Rela <80651Ah, 8, 0> ; R_X86_64_RELATIVE [0x8040E4] = [0x8040E4] + [0x8040E4] LOAD:000000000080653A Elf64_Rela <806562h, 200000005h, 0> ; R_X86_64_COPY LOAD:0000000000806552 Elf64_Rela <8040E4h, 500000001h, 0> ; R_X86_64_64 [0x8040E4] = [0x8040E4] + [0x8040E4] LOAD:000000000080656A Elf64_Rela <806562h, 8, 0> ; R_X86_64_RELATIVE LOAD:0000000000806582 Elf64_Rela <8040E4h, 500000001h, 8042BAh> ; R_X86_64_64 +8042BAh [0x8040E4] = [0x8040E4] + [0x8042BA] ; SBOX[0] LOAD:000000000080659A Elf64_Rela <8042BAh, 500000005h, 0> ; R_X86_64_COPY [0x8042BA] = [[0x8040E4]] 注意这里的memcpy, 用的不再是2号,而是5号,即相当于memcpy(0x8042BA, [0x8040E4], [0x8040EC]) LOAD:00000000008065B2 Elf64_Rela <8065CAh, 200000005h, 0> ; R_X86_64_COPY [0x8065CA] = [0x8040E4]; 0x80409C 的值自 80647A 一直没被修改过,仍为0x8040E4 LOAD:00000000008065CA Elf64_Rela <0, 600000001h, 0> ; R_X86_64_64 [[0x8040E4]] = [0x8040FC] + 0 这里开始重复了,和00000000008062FA一致 LOAD:00000000008065E2 Elf64_Rela <80409Ch, 8, 8042C2h> ; R_X86_64_RELATIVE +8042C2h
提取出关键部分,总结下来:
1 2 3 4 5 6 7 8 9 10 11 12 13 [0x8040CC] = 0 [0x8040CC] = [0x8040CC] + [0x8042BA] byte ptr [0x804114] = byte ptr [0x804040] [0x806412] = [0x806412] [0x8040CC] = [0x8040CC] + [0x804114] dword ptr [0x8040CD] = dword ptr [0x804084] + 0 [0x8040FC] = [0x8042BA] [0x8040E4] = [0x8040CC] + [0x8040CC] [0x8040E4] = [0x8040E4] + [0x8040E4] [0x8040E4] = [0x8040E4] + [0x8040E4] [0x8040E4] = [0x8040E4] + [0x8042BA] [0x8042BA] = [[0x8040E4]] [[0x8040E4]] = [0x8040FC] + 0
到这里不难发现虚拟机结构。另80407C开始的Elf_Sym64结构体为寄存器
r1-r7,r1永远为0, w1-w7 为 x1-x7 的低 32bit, m4
代表r4 & 0xFFFFFFFF00的部分
用伪代码写上述过程为:
1 2 3 4 5 6 7 8 9 10 11 12 mov r4, 0 add r4, r4, S[0] mov b7, serial[0] add r4, r4, r7 add m4, w1, 0 mov r6, S[0] add r5, r4, r4 add r5, r5, r5 add r5, r5, r5 add r5, x5, &S[0] mov S[0], [r5] add [r5], r6, 0
再手动反编译一下,用伪代码写就是:
1 2 3 4 5 j = 0 j = j + S[0] + serial[0] tmp = S[0] S[0] = S[j] S[j] = tmp
这里是RC4的初始化部分。
接下来就是刚出剩下的部分了。解题的时候是调试+硬看的,没有脚本。
第一部分是用flag的每两位初始化RC4,然后加密b""的结果,再乘以一个矩阵。注意RC4并不是标准的,加密循环i+1的位置和标准RC4不同。写脚本提取数据,求解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 from pwnlib import elffrom numpy import *elf = elf.ELF("/home/apeng/CTF/GoogleCTF/ELDAR/eldar" ) rela_section = elf.sections[10 ] rela_size = len (rela_section.data()) // rela_section.entry_size i = 64603 ed = 93676 -200 A = [] B = [] while i < ed: tmp_a = [] is_end = 0 while is_end == 0 : reloc = rela_section.get_relocation(i) if reloc["r_offset" ] == 0x804114 : if reloc["r_info" ] == 8 : res = reloc["r_addend" ] i += 1 a = 0 while True : reloc = rela_section.get_relocation(i) if reloc["r_offset" ] == 0x80409C : x = reloc["r_addend" ] if 0x804ACA <= x <= 0x804ACA +0x18 : x_str = f"x[{x - 0x804ACA } ]" elif x == 0x8040FC : b_str = f"a" elif x == 0x8040E4 : b_str = f"x" i += 1 continue if reloc["r_info" ] & 0xFFFFFFFF == 1 : tmp = reloc["r_offset" ] if tmp == 0x804114 : tmp_a.append(a) break elif tmp == 0x8040FC : if b_str == "a" : a += a elif b_str == "x" : a += 1 i += 1 continue elif tmp == 0x8040CC : is_end = 1 break else : print (f"{tmp:#x} " ) i += 1 continue i += 1 A.append(tmp_a) B.append(-res) i += 1 for i in range (len (A)): print (A[i], B[i]) mA = mat(A) mB = mat(B).reshape((24 , 1 )) mX = mA.I * mB res = list (map (lambda x: int (round (x)), mX.reshape(1 , 24 ).tolist()[0 ])) def rc4 (key ): r = [] S = [i for i in range (256 )] j = 0 for i in range (0x100 ): j = (j + S[i] + key[i % 2 ]) % 256 tmp = S[i] S[i] = S[j] S[j] = tmp S[S[0 ]] i = 0 j = 0 for k in range (3 ): j = (j + S[i]) % 256 tmp = S[i] S[i] = S[j] S[j] = tmp k = S[(S[i] + S[j]) % 256 ] r.append(k) i += 1 return r dic = {} for i in range (0x20 , 0x7f ): for j in range (0x20 , 0x7f ): key = bytes ([i, j]) dic[bytes (rc4(key))] = key flag = b"" for i in range (0 , len (res), 3 ): flag += dic[bytes (res[i:i+3 ])] print (flag)
第二部分还是个矩阵运算,不过用了什么特别 操作使得某些
rela
可以执行代码,以加入了位运算。具体原理没仔细分析,调出来之后用z3解:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 import structfrom capstone import *from pwnlib import elffrom numpy import *elf = elf.ELF("/home/apeng/CTF/GoogleCTF/ELDAR/eldar" ) rela_section = elf.sections[10 ] rela_size = len (rela_section.data()) // rela_section.entry_size i = (0x0000000000A293F2 - 0x0000000000804272 ) // 0x18 ed = (0x0000000000A579CA - 0x0000000000804272 ) // 0x18 A = [] B = [] while i < ed - 100 : tmp_a = [] last = None is_end = 0 while is_end == 0 : reloc = rela_section.get_relocation(i) if reloc["r_offset" ] == 0x804114 : if reloc["r_info" ] == 8 : res = reloc["r_addend" ] i += 1 a = 0 while True : reloc = rela_section.get_relocation(i) if reloc["r_offset" ] == 0x80409C : x = reloc["r_addend" ] if 0x804ACA <= x <= 0x804ACA +0x18 : x_str = f"x[{x - 0x804ACA } ]" elif x == 0x8040FC : b_str = f"a" elif x == 0x8040E4 : b_str = f"x" i += 1 continue if reloc["r_info" ] & 0xFFFFFFFF == 1 : tmp = reloc["r_offset" ] if tmp == 0x804114 : if a != 0 : tmp_a.append(a) break elif tmp == 0x8040FC : if b_str == "a" : a += a elif b_str == "x" : a += 1 i += 1 continue elif tmp == 0x8040CC : is_end = 1 break else : print (f"{tmp:#x} " ) if reloc["r_offset" ] == 0x804000 : i += 1 reloc = rela_section.get_relocation(i) code = struct.pack("q" , reloc["r_addend" ]) cs = Cs(CS_ARCH_X86, CS_MODE_64) cs.detail = True c = list (cs.disasm(code, 0 ))[0 ] s = c.op_str.split(", " )[1 ] tmp_a.append(f"{c.mnemonic} {s} " ) last = f"{c.mnemonic} {s} " i += 1 break i += 1 continue i += 1 A.append(tmp_a) B.append(-res) i += 1 for i in range (len (A)): print (A[i], B[i]) from z3 import *x = [BitVec(f"x{i} " , 9 ) for i in range (12 )] s = Solver() def rol (x, v ): v %= 8 return ((x << v) | (x >> (8 -v))) & 0xFF def ror (x, v ): v %= 8 return ((x >> v) | (x << (8 -v))) & 0xFF for i in range (len (A)): sum = 0 for j in range (len (A[i])): if type (A[i][j]) == int : sum += x[j] * A[i][j] else : code = A[i][j] op, val = code.split(" " ) val = int (val, 16 ) if op == "and" : sum += x[j] & val elif op == "or" : sum += x[j] | val elif op == "xor" : sum += x[j] ^ val elif op == "rol" : sum += rol(x[j], val) elif op == "ror" : sum += ror(x[j], val) elif op == "shl" : sum += (x[j] << val) & 0xFF elif op == "shr" : sum += (x[j] >> val) & 0xFF else : print (op) exit(-2 ) s.add(sum == B[i]) print (s.check())m = s.model() flag = [] for i in x: flag.append(m[i].as_long()) print (bytes (flag))