2018 LCTF
LCTF 逆向 wirteup
比赛日期:2018.11.17-2018.11.18
此次比赛先后放出了共7道题。我在比赛中只做出了easyvm,game两题,其余题目为赛后复现,参考了pizza的做法。
拿去签到吧朋友
直接运行是正常的,打开ida后再运行会直接退出,必定有反调试。查找exit函数,查找引用,在0040130E有一个调用,在00401408有一个调用,全部nop或者jmp掉就行了。如果你是单步跟踪,能看到sub_401451有一个smc函数。如果一开始跳过了整个开头直接call
main函数,就会漏掉这个,对后面必然有影响。
接下来分析main函数。首先校验长度36,然后对输入的数据构建了一个数据结构。进入构建函数0040174C分析一波,能看出它是一个二叉树,采用结构体数组的方式存储。定义结构体:
1 | 00000000 BiTree struc ; (sizeof=0x10, mappedto_14) |
对相关变量定义好,整个函数的结构就清晰了。构架二叉树的方法:从根节点开始往下,大的放右边,小的放左边,有数据了就再次比较,以此类推。
004017DD是先序遍历,遍历得到数据和下标,sub_401D6E函数是加密与校验。发现字符串falconn,之后又36轮加密,每一轮把字符串的每个字节转为二进制放入八个字节,然后按照00409880的规则置换。看到置换表,熟悉密码学的选手就能认出是DES加密了(参考)。对加密过程的每一步对比DES,可以看出完全一致。字符串falconn作为key,加密的数据放入0040C100。前36个作为一个矩阵,乘一个常量矩阵,然后跟一个常量矩阵比对,然后单独比对最后四个密文。之后再对比一遍前序遍历前18位的下标。这样可以解密得到flag的前18位。
接下来跟之前相似,0040188E是后序遍历。与之前不同,加密函数被smc了,而这一部分在开头又被smc了。进入调试,输入之前求出的先序遍历,在00401E79设下断点。
但是试了好几次,00401E7A函数并没有被还原成功,回头看看smc
调试好多次,终于发现了问题所在。在sub_401451的smc中,目标函数异或了反调试函数,如果修改反调试函数,那目标函数最终也变了,所以之前不能对反调试函数修改,要在动调中通过对内存或寄存器的修改来避开反调试。
发现了问题,那就开始尝试新的方法,还好做题之前有备份。拖进x32dbg里,从头开始动调,遇到反调试的地方改内存/寄存器/IP,最后停在目标函数那里。但是当我尝试了好几次之后,还是效果不好,总是会出各种问题。思前想后终于想到一种方法,把exit函数的内容改成ret,这样就不会退出了。调试到00401E79,这回终于还原成功了!
来到函数00401E79
1 | .text:00401E81 mov eax, offset loc_401E88 ; Keypatch modified this from: |
这里有jmp
eax,在动调中ida不能很好的分析函数,手动把00401E81改成jmp , offset loc_401E88,这样就可以f5了,可以分析这个加密函数了。加密的方式特别简单,直接写出脚本解密。像之前那一段一样,对比下标解出后一段flag。
脚本:
1 | from numpy import* |
easyvm
vm题。
首先在603080可以看到三段bytecode,每个指令是一个qword。在sub_4009D2执行三段bytecode。401722完成了对寄存器的初始化。分析这个初始化函数可以得到此vm的寄存器结构:
1 | 00000000 vm struc ; (sizeof=0xCC8, mappedto_8) |
分析清结构体,接下来的操作函数401502也更加清晰了。逐条对bytecode分析,最终可以得出程序的目的:
bytecode分析参考
1.计算输入长度,校验是否等于0x1C
2.将输入的每一位ch进行如下操作:
ch=((ch*0x3f)+0x78)%0x80
3.与常量校验。
加密的算法很简单,写脚本爆破flag即可。
1 | a=[0x3E,0x1A,0x56,0x0D,0x52,0x13,0x58,0x5A,0x6E,0x5C,0x0F,0x5A,0x46,0x07,0x09,0x52,0x25,0x5C,0x4C,0x0A,0x0A,0x56,0x33,0x40,0x15,0x07,0x58,0x0F] |
enigma
根据题目,这题的算法应该跟enigma类似。enigma是二战时期纳粹德国使用的一种密码。
用ida打开,跟着输入进入sub_4730。然而先后看了几个函数,发现都在跟一些变量比对,变量的来源不明,静态分析卡住了,上动调。
动态调试的时候,不难分析出sub_4730中的第一个函数sub_4320是判定输入是否位大写字母。与此同时也能看出,这是用C++写出来的。中途我们能看出它的虚表结构。尝试正面刚它的算法的话肯定十分痛苦,想想其他方法。
在此之前先看看最后校验的地方。很快能发现:
if ( n != qword_94A8 || n && memcmp(s1, s2, n) )
这里的n应该是输入的长度,s1和s2是密文对比。设下断点,调试过去果真如此,得到长度15和密文DQYHTONIJLYNDLA。
我们思考一下enigma的算法。查询资料可以知道这是一种流密码。这种密码一次以一个元素(一个字母,或是说一个字节)作为基本单元。而enigma加密的时候后面的每一位不会对之前加密的结果有任何影响,每输入一个字符,立刻就有一个字符输出。比如输入A,输出A,不管后面再跟什么,这个A都不会有改变。这就意味着如果想爆破这个密码,只需要15*26次,而不是15的26次方次。只要我们能随时得到密文的输出,就能轻易地爆破了。
在结尾附近找找,哪里适合修改。我们不妨在比较错误的地方直接让他输出加密得到的密文。来到地址00000000000027FD,这里输出了常量You have,我们想把它改成密文s1; // [rsp+B0h] [rbp-88h],然而密文是在栈上的,直接改的话会多一个字节的长度。(lea rdi, aYouHave为7个字节,lea rdi, [rsp+138h+s1]为八个字节)不过问题不大,连带上面一个jz改掉就够了,这样同时比对完长度直接就会输出密文,效果更好。打好补丁放到linux运行一下,可以看到直接输出了密文。
接下来可以爆破明文了。手动爆破是不可能手动的,这辈子都不可能手动的。用pwntools可以轻松帮我们搞定。脚本如下:
1 | from pwn import * |
maze
在做了enigma之后,又想用同样的方法了呢= =
先看看这题的加密方法,相似的,修改文件内容使之直接输出密文。
先调试一圈下来,在38B1发现了合适的修改点:
1 | .text:00000000000038B1 lea rdi, [rbp+var_60] ; a1 |
这样程序就会直接输出密文。多试几次能发现规律,后面的输入不会影响前面的2*i+2位
于是:
1 | from pwn import * |
MSP430
拿到手是一个接线图,一个hex文件,一个hex转成elf的.out,一个输出的内容图片
出题人已经告诉我们了单片机型好MSP430G2553。用ida打开lctf.out,在processor type中选择MSP430,就可以反汇编了。但是ida对msp430的分析优化不足,有些东西会缺失(也可能是hex转成的elf出了问题),只能连蒙带猜的做。
先去找一份msp430的指令集,对着指令集看汇编。
函数名和一些全局变量名都保留了,还是有突破口的,现在函数名内浏览一遍,发现了RC4 keygen main 等函数,大概猜到用的是RC4。先从main函数开始看。先call keygen函数,参数是全局变量key的地址(R12),这里应该是key初始化的函数。
1 | .text:0000C296 keygen: ; CODE XREF: main+2C↑p |
分析这个keygen函数,先把一个0x28地址的内容放到R15,我猜这里是出了问题的,所以并不知道地址里放了什么东西,假设这个数据为i,后面几句就比较清晰了,key[4]=i*3, key[5]=i*2,key[6]=i&0x74,key[7]=i+0x50;这里只得到了后四位key,剩下的部分暂时不知道。
接下来回到main继续。在RC4_code的参数中有8,猜测是key的长度。找一下字符串,看到只有0123456789abcdefLCTF0000这个字符串,最后四位都是0,感觉是把之前的四位填进去了,所以猜测key是LCTFxxxx。后四位都是从一个byte数据得到的,所以可以尝试爆key。脚本如下:
1 | from Crypto.Cipher import ARC4 |
直接可以得到flag,也是比较幸运
game
打开后是一个游戏,提示说赢了就能得到flag,直接在判定输赢的地方设断点,直接跳到赢就可以得到falg了
000000000040248F改成jmp
00000000004024B2nop掉
00000000004024C2nop掉
然后打开游戏按个空格就有flag了= =
b2w
解压出来是一个elf程序,一个out.wav文件。
用ida打开,进入main函数。整个程序是在把一堆bmp文件和合成为一个wav文件。sub_401C6D时最终写入wav文件的部分。这里先看到一串长得像flag的东西,但它的提示说这并不是flag。可以看到他依次写入了一些文件头和wav的数据。写完之后有干了点额外的事情——把文件加密。
1 | for ( i = 0; a1->lenth > i; ++i ) |
可以看到它的加密是用一些很简单的异或实现的。异或的key就是之前的假flag。查一些资料可以知道,wav的声音文件是可以转成图像的,类似示波器,李萨如图形等。很有可能未被加密的wav文件里面就藏有flag的信息。先写脚本将原本的wav还原:(python2脚本)
1 | from struct import unpack |
得到的dec.wav用GoldWave打开,然后在图像区域右键选择X-Y模式,可清晰的看到:
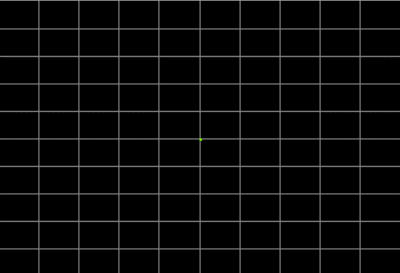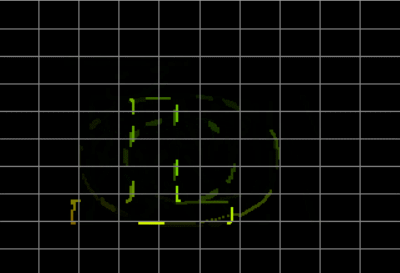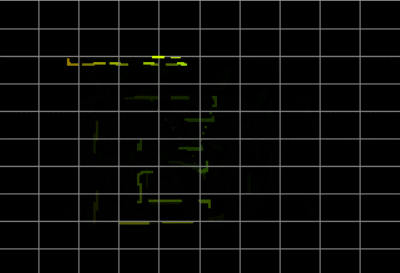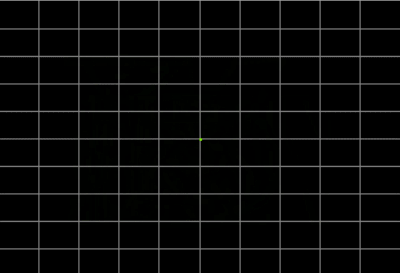
这里的字符是上下左右颠倒的,不过都是大写字母很容易识别,用肉眼看就可以了。Goldwave软件里可以调整速度,也可以反复看某一段。注意别漏了下划线。